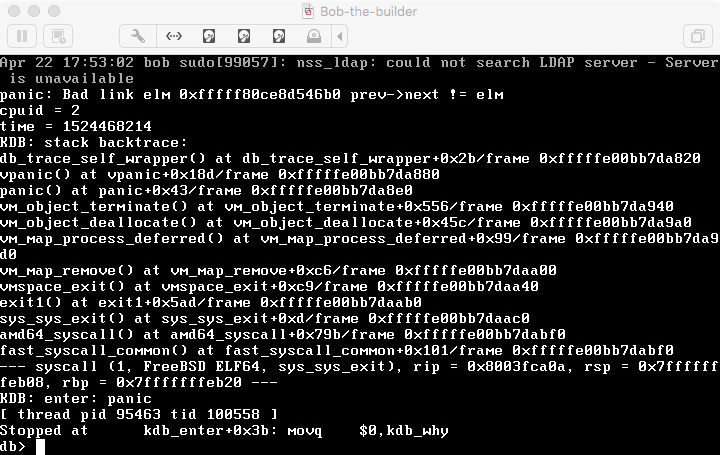
On 29/05/2018 19:22, Mark Johnston wrote: > On Tue, May 29, 2018 at 04:50:14PM +0300, Andriy Gapon wrote: >> On 23/04/2018 17:50, Julian Elischer wrote: >>> back trace at: http://www.freebsd.org/~julian/bob-crash.png >>> >>> If anyone wants to take a look.. >>> >>> In the exit syscall, while deallocating a vm object. >>> >>> I haven't see references to a similar crash in the last 10 days or so.. But if >>> it rings any bells... >> >> We have just got another one: >> panic: Bad link elm 0xfffff80cc3938360 prev->next != elm >> >> Matching disassembled code to C code, it seems that the crash is somewhere in >> vm_object_terminate_pages (inlined into vm_object_terminate), probably in one of >> TAILQ_REMOVE-s there: >> if (p->queue != PQ_NONE) { >> KASSERT(p->queue < PQ_COUNT, ("vm_object_terminate: " >> "page %p is not queued", p)); >> pq1 = vm_page_pagequeue(p); >> if (pq != pq1) { >> if (pq != NULL) { >> vm_pagequeue_cnt_add(pq, dequeued); >> vm_pagequeue_unlock(pq); >> } >> pq = pq1; >> vm_pagequeue_lock(pq); >> dequeued = 0; >> } >> p->queue = PQ_NONE; >> TAILQ_REMOVE(&pq->pq_pl, p, plinks.q); >> dequeued--; >> } >> if (vm_page_free_prep(p, true)) >> continue; >> unlist: >> TAILQ_REMOVE(&object->memq, p, listq); >> } >> >> >> Please note that this is the code before r332974 Improve VM page queue scalability. >> I am not sure if r332974 + r333256 would fix the problem or if it just would get >> moved to a different place. >> >> Does this ring a bell to anyone who tinkered with that part of the VM code recently? > > This doesn't look familiar to me and I doubt that r332974 fixed the > underlying problem, whatever it is. I see. >> Looking a little bit further, I think that object->memq somehow got corrupted. >> memq contains just two elements and the reported element is not there. > > Based on the debugging session, it would be interesting to know if there > were any other threads somehow manipulating the (dead) object at the > time of the panic. I will check for this. > Among the panics that you observed, is it the same application that is > causing the crash in each case? I have two crash dumps right now and in both cases it's sh exec-ing grep. But I cannot imagine what could be so special about that. Actually, I see that the shell ran a long pipeline with many grep-s in it, so there were many exec-s and exits of grep, perhaps some of them concurrent. -- Andriy GaponReceived on Tue May 29 2018 - 14:38:30 UTC
This archive was generated by hypermail 2.4.0 : Wed May 19 2021 - 11:41:16 UTC
{kind=link}