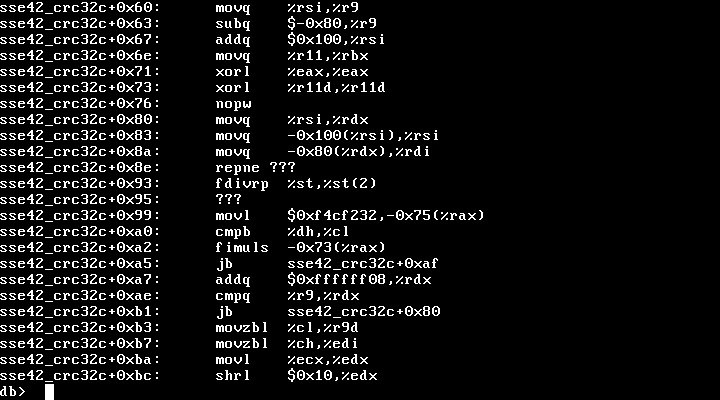
On Thu, Sep 26, 2019 at 02:12:21PM -0600, Alan Somers wrote: > On Thu, Sep 26, 2019 at 11:29 AM Konstantin Belousov <kostikbel_at_gmail.com> > wrote: > > > On Thu, Sep 26, 2019 at 11:20:51AM -0600, Alan Somers wrote: > > > On Thu, Sep 26, 2019 at 11:02 AM Konstantin Belousov < > > kostikbel_at_gmail.com> > > > wrote: > > > > > > > On Thu, Sep 26, 2019 at 09:45:43AM -0600, Alan Somers wrote: > > > > > The latest VM snapshot > > > > (FreeBSD-13.0-CURRENT-amd64-20190920-r352544.qcow2) > > > > > instapanics on boot: > > > > > > > > > > panic: Unregistered use of FPU in kernel > > > > > > > > > > stack trace: > > > > > ... > > > > > sse42_crc32c > > > > > readsuper > > > > > ffs_sbget > > > > > g_label_ufs_taste_common > > > > > g_label_taste > > > > > g_new_provider_event > > > > > g_run_events > > > > > fork_exit > > > > > ... > > > > > > > > > > Has anybody touched this area recently? I'll try to narrow down the > > > > commit > > > > > range. > > > > > > > > Start with disassembling the faulting instruction. I suspect that > > somehow > > > > vital compiler switches like -mno-sse got omitted in the build. > > > > > > > > > > No problem with compiler switches here. The C file uses inline assembly > > to > > > generate a crc32q instruction, in crc32_sse42.c:257. But why would that > > > generate a floating point exception? The instruction doesn't appear to > > be > > > using any floating point registers. This is on a Kaby Lake CPU. > > > > > > crc32q %rsi, %rbx > > > > No idea, this instruction does not generate #NP at all. > > > > Provide exact script of the panic and backtrace, > > together with the disassembly of the function which contained the faulted > > instruction. Do disassemble from ddb, in case text was corrupted. > > > > Ok, here's the full stack trace: > #0 __curthread () at /usr/src/sys/amd64/include/pcpu_aux.h:55 > #1 doadump (textdump=0) at /usr/src/sys/kern/kern_shutdown.c:392 > #2 0xffffffff804a1edb in db_dump (dummy=<optimized out>, > dummy2=<optimized out>, dummy3=<unavailable>, dummy4=<unavailable>) > at /usr/src/sys/ddb/db_command.c:575 > #3 0xffffffff804a1c8f in db_command (last_cmdp=<optimized out>, > cmd_table=<optimized out>, dopager=1) at > /usr/src/sys/ddb/db_command.c:482 > #4 0xffffffff804a1a04 in db_command_loop () > at /usr/src/sys/ddb/db_command.c:535 > #5 0xffffffff804a4cbf in db_trap (type=<optimized out>, code=<optimized > out>) > at /usr/src/sys/ddb/db_main.c:252 > #6 0xffffffff80c1e55c in kdb_trap (type=3, code=0, tf=<optimized out>) > at /usr/src/sys/kern/subr_kdb.c:692 > #7 0xffffffff811957df in trap (frame=0xfffffe00907e8d20) > at /usr/src/sys/amd64/amd64/trap.c:621 > #8 <signal handler called> This is not a useful trace. It only shows the ddb part after the trap. Please show all console messages around the panic, as was requested. > > Your guess about corrupted text was prescient. Here is the disassembly > according to ddb: > https://people.freebsd.org/~asomers/Screenshot_fbsd-head_2019-09-26_13%3A51%3A34.png > And here is the disassembly of the same section according to gdb: > 0xffffffff8113b2e0 <sse42_crc32c+96>: mov %rsi,%r9 > 0xffffffff8113b2e3 <sse42_crc32c+99>: sub $0xffffffffffffff80,%r9 > 0xffffffff8113b2e7 <sse42_crc32c+103>: add $0x100,%rsi > 0xffffffff8113b2ee <sse42_crc32c+110>: mov %r11,%rbx > 0xffffffff8113b2f1 <sse42_crc32c+113>: xor %eax,%eax > 0xffffffff8113b2f3 <sse42_crc32c+115>: xor %r11d,%r11d > 0xffffffff8113b2f6 <sse42_crc32c+118>: nopw %cs:0x0(%rax,%rax,1) > 0xffffffff8113b300 <sse42_crc32c+128>: mov %rsi,%rdx > 0xffffffff8113b303 <sse42_crc32c+131>: mov -0x100(%rsi),%rsi > 0xffffffff8113b30a <sse42_crc32c+138>: mov -0x80(%rdx),%rdi > 0xffffffff8113b30e <sse42_crc32c+142>: crc32q %rsi,%rbx > 0xffffffff8113b314 <sse42_crc32c+148>: crc32q %rdi,%rax > 0xffffffff8113b31a <sse42_crc32c+154>: mov (%rdx),%rsi > 0xffffffff8113b31d <sse42_crc32c+157>: crc32q %rsi,%r11 > 0xffffffff8113b323 <sse42_crc32c+163>: lea 0x8(%rdx),%rsi > 0xffffffff8113b327 <sse42_crc32c+167>: add $0xffffffffffffff08,%rdx > 0xffffffff8113b32e <sse42_crc32c+174>: cmp %r9,%rdx > 0xffffffff8113b331 <sse42_crc32c+177>: > jb 0xffffffff8113b300 <sse42_crc32c+128> > 0xffffffff8113b333 <sse42_crc32c+179>: movzbl %cl,%r9d > 0xffffffff8113b337 <sse42_crc32c+183>: movzbl %ch,%edi > 0xffffffff8113b33a <sse42_crc32c+186>: mov %ecx,%edx > > Care to guess what's causing the corruption? I agree with cem that it is more likely ddb disassembler unable to handle some aspects, and that looking at hex bytes of the faulted instruction is the interesting data.Received on Thu Sep 26 2019 - 18:33:58 UTC
This archive was generated by hypermail 2.4.0 : Wed May 19 2021 - 11:41:22 UTC
{kind=link}